In this post, let’s learn about what is Inference in the context of machine learning and how it is different from Training. Then we’ll learn about their importance in the world of machine learning.
What is Inference? Link to heading
Training machine learning models is akin to teaching concepts or skills to a toddler. Imagine teaching a toddler what a cat and dog looks like by showing them many pictures of cats and dogs. After this said training task, the toddler would have learned the visual patterns that characterizes cats and dogs.
Now, when you show the toddler a new picture of a cat or a dog, say this new picture is a different breed of a cat or a dog that the toddler has never seen before, in other words - was not trained on, and ask “What’s in the picture?”, the toddler can look at this new picture with a fair certainity, and identify if it is a cat or a dog. In other words, the toddler is able to infer cats and dogs on new data - this is called inference!
In machine learning, models are trained or go through a training phase, during this phase the model learns patterns from large amounts of data. For example, a model can be trained on thousands of labeled images of cats and dogs to learn the patterns that characterize cats and dogs. Once trained sufficiently, the model can be given new, unseen images of cats or dogs and asked “What is in the picture?” the model then predicts the label (type) of the image with certain confidence.
The process of taking a trained model and making predictions on new data points is called inference.
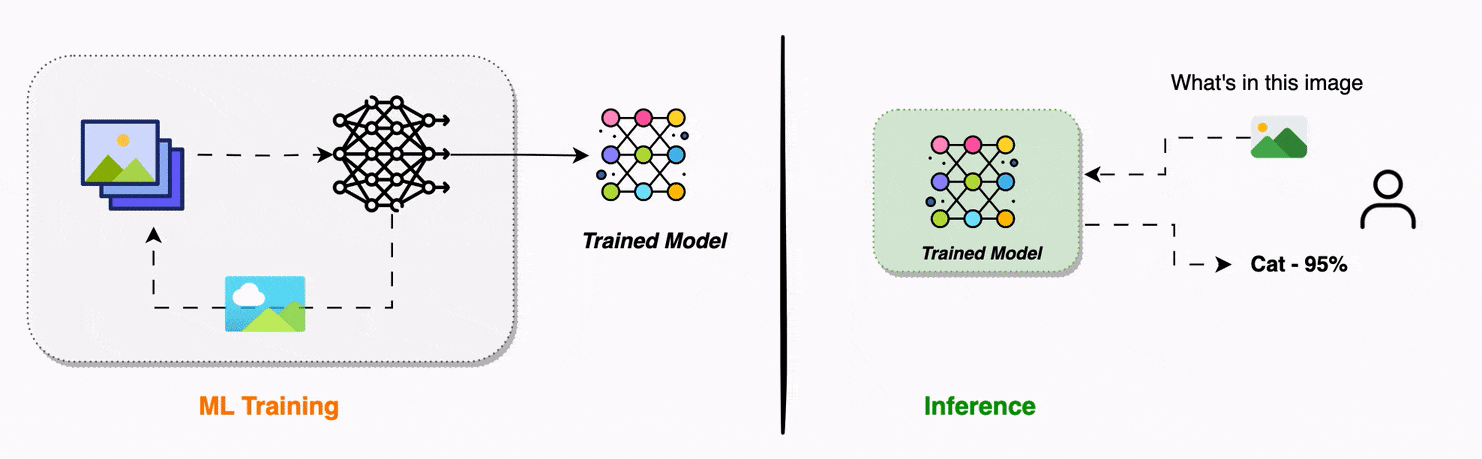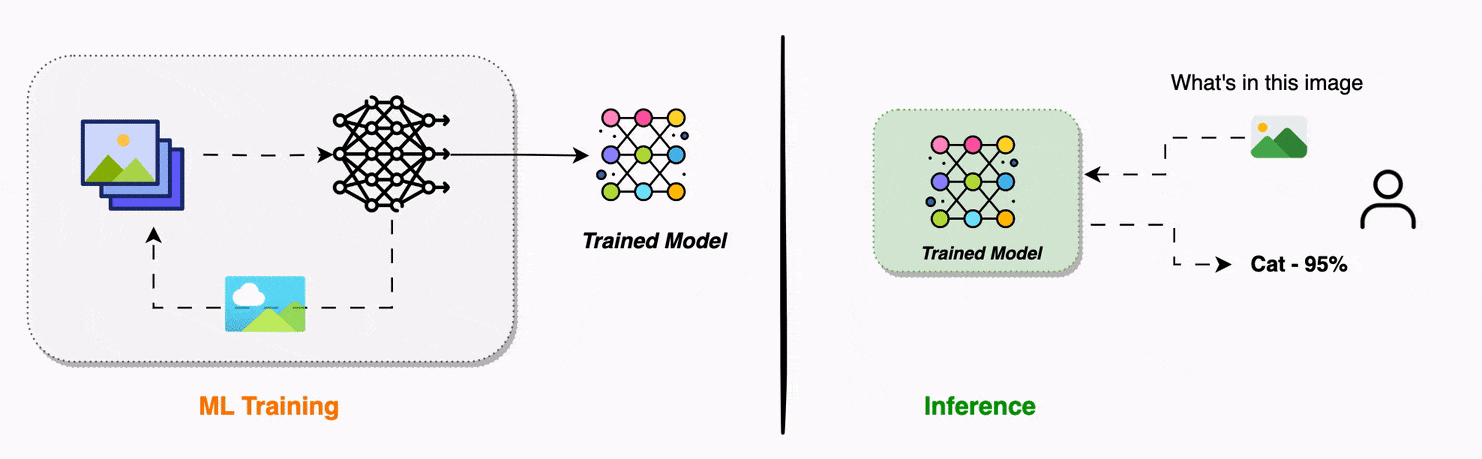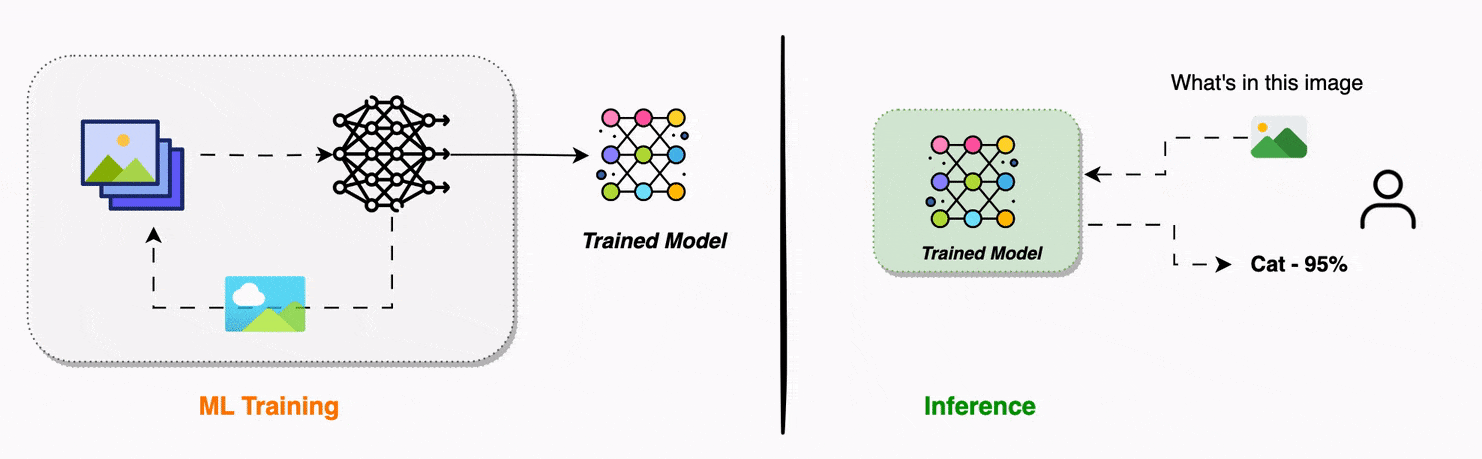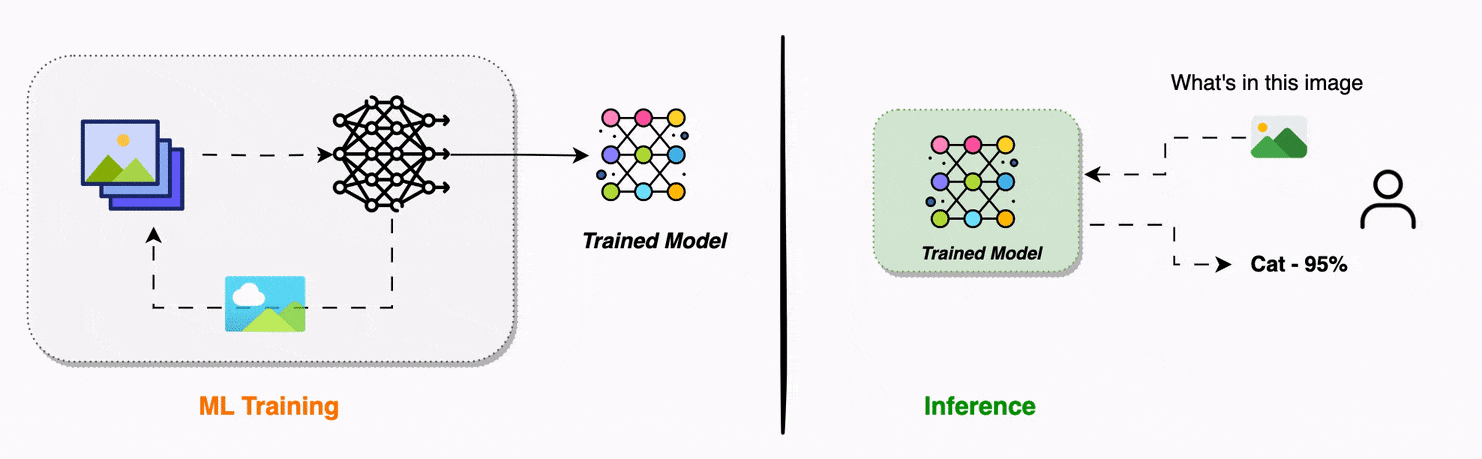
So in short, training is teaching the model to learn patterns in data and inference is process of using or applying a trained model to make predictions. In other words, training enables the model to learn, inference allows it to predict.
Building a useful machine learning system requires both robust training and streamlined inference.
Inference in real life Link to heading
Ever interacted with a chatbot? Most of us are familiar with OpenAI’s ChatGPT or Anthropics’ Claude chatbots.
When you type in a question in ChatGPT or Claude and hit enter, the model behind chat interface (GPT-3.5/4 or Claude 2) streams the response back to you in a very quick fashion. This speed in response that you experience is thanks to highly optimized inference servers that host these trained models and serve thousands of requests per second in parallel.
Inference servers are optimized for low latency (speed) and high throughput (serving requests simultaneously) so that it can serve millions of requests per second. They are optimized to handle high volumes of requests with low latency. More often than not, inference servers are hosted in a distrubuted fashion so that the load can be shared across multiple servers.
Now that we understand what inference is, let’s learn a bit more about inference servers.
Inference Servers Link to heading
So, what is an inference server? - At a high level, an inference server is a software component that hosts a trained machine learning model and provides an API to make predictions on new and unseen data.
For example, say you have a weather forecasting model that is trained to predict rainfall based on conditions like temperature, humidity, wind etc. Now, to use this forecasting model to predict rainfall, we need to host this trained model onto an inference server.
Now, as new weather data comes in, we send this new data as input to trained model on the inference server, this data is then run through the hosted rainfall prediction model, and the model returns the probability of rainfall (prediction) on that day.
The key purpose of an inference server is to take in inference requests, run them efficiently through the hosted models, and return predictions. Ideally, the inference servers should be optimized to handle high volumes of requests with low latency.
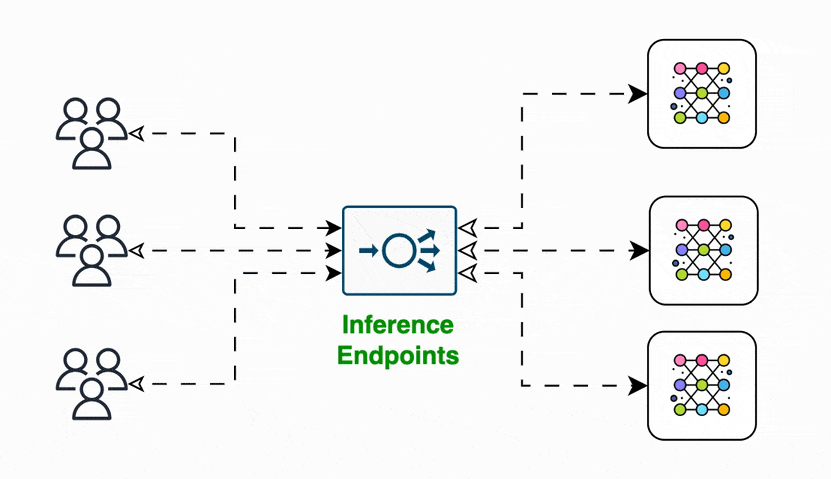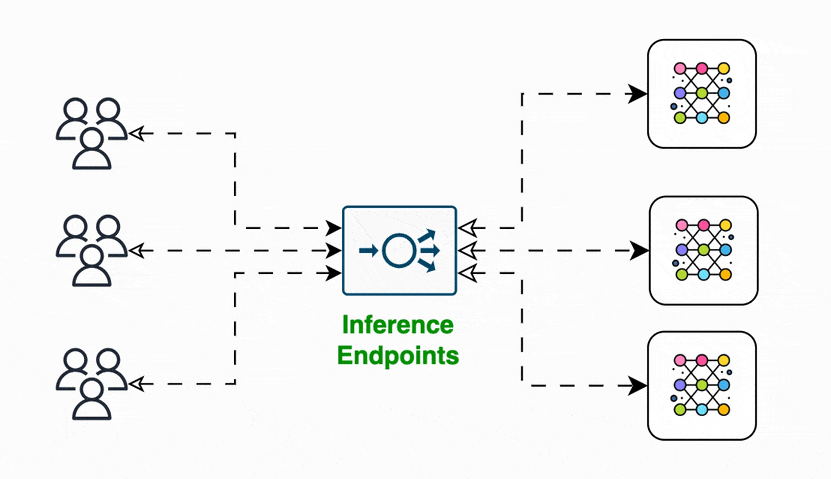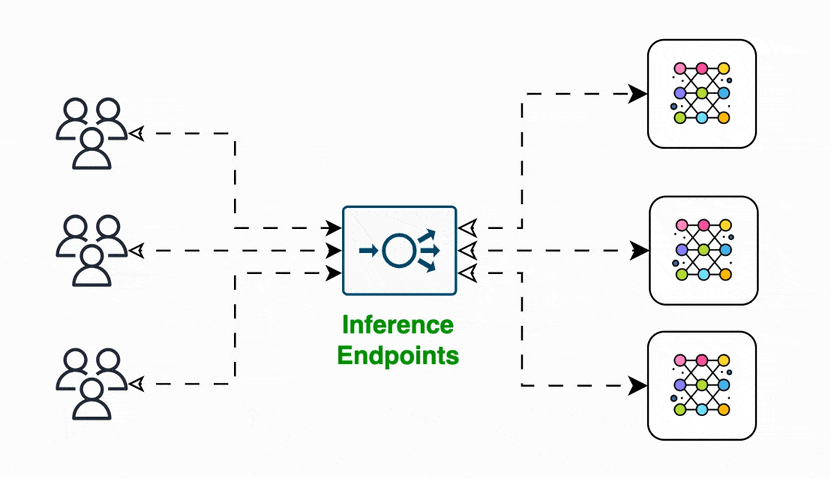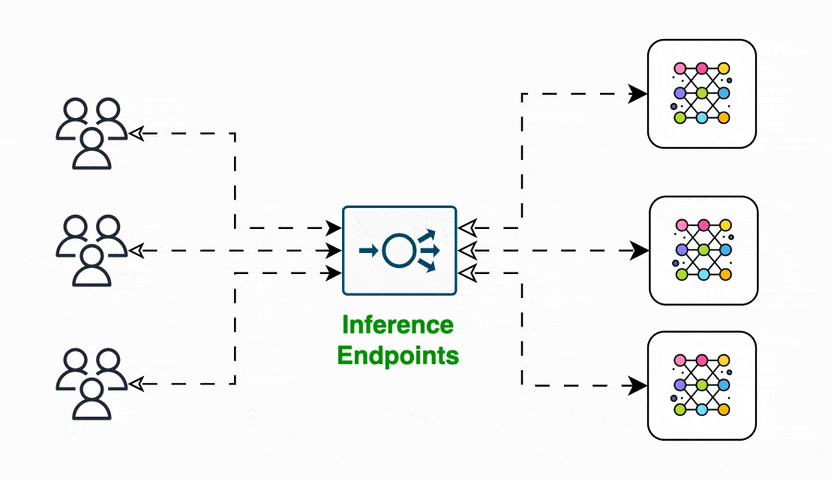
Use cases for Inference Servers Link to heading
Inference servers are used in a wide variety of applications. Some examples include:
Home Assistants:
Think of a smart speaker like Alexa. It uses speech recognition models hosted on inference servers to listen to your voice and convert it to text in real-time so Alexa can understand your request.
Self-driving cars:
Self-driving cars also use inference servers to host models that can make sense of visual data and make quick predictions to drive safely.
Large-scale data processing:
Need to extract huge amounts information from data sources like emails, documents, images etc.? Rather than manually reviewing everything, you could host a trained document classification model or an image recognition models onto inference servers to process the data at scale and automatically extract relevant information for downstream tasks.
In essence, to take models from prototype to production you need Inference servers!
Benefits of Inference servers Link to heading
- They allow use of trained models for predictions by hosting the trained model and providing an API for inference.
- Inference servers can host multiple models and model versions simultaneously, enabling easy A/B testing.
- By coupling with autoscaling and load balancing, inference endpoints can scale seamlessly to handle increased inference requests.
- They are capable of hosting models developed in popular machine learning frameworks like PyTorch, TensorFlow etc. and can be queried from any device.
In summary, inference servers provide the infrastructure to take trained ML models and apply them effectively in real-world applications. They alleviate deployment hassles so you can focus on building models!
Can Inference Servers run on commodity hardware? Link to heading
Yes, most inference servers can run on commodity hardware. They are designed to run on commodity hardware or can be deployed on any cloud or on-premise infrastructure. Most inference server softwares are open-source and are typically deployed in a containerized format.
Here are a few examples of inference servers that can run on commodity hardware:
For e.g., AWS offers a wide variety of managed containerized inference servers as docker images, called AWS Deep Learning Containers (DLC’s), that can be deployed on AWS Infrastructure instance types.
Note: when trained model are deployed for inference, the inference environment should also include all the necessary software packages like Python, TensorFlow, PyTorch etc. that the model was trained on. So, when containerizing inference images we need to ensure that these software dependencies are also baked into the image.
For a full list of available DLC’s on AWS, refer to the available images on AWS github repo.
Summary Link to heading
In this post, we learned about inference and inference servers. But there is a lot more that goes into building a production-ready inference server.
- Can we take a trained model and deploy it as is to an inference server?
- Are there other ways to optimize models for inference?
- What are various model optimization techniques that we could apply for better inference?
In the next post, we’ll answer some of the common questions around building optimized inference servers.
Happy Learning!